Integrating Ollama
🦙 Ollama is a free, open-source tool that lets you run large language models (LLMs) on your own computer. (hardware must meet requirements)
Download and Install Ollama
You can download Ollama from https://ollama.com.
Select and Pull a Model
Choose the model you want to use at https://ollama.com/search.
In the terminal (PowerShell on Windows), enter ollama pull <model_name> to download the model.
model_name format: <model_name>:<model_version>. For example, deepseek-r1:8b.
The 8b parameter model requires at least 16GB of video memory (VRAM). Refer to other documentation for detailed information on configurations and parameter sizes.
After pulling is complete, use ollama list to view the models you have pulled.
Then use ollama run <model_name> to run the model.
Configure AstrBot
Open the AstrBot WebUI, locate Service Provider Management, click on Add Provider, find and click on Ollama. 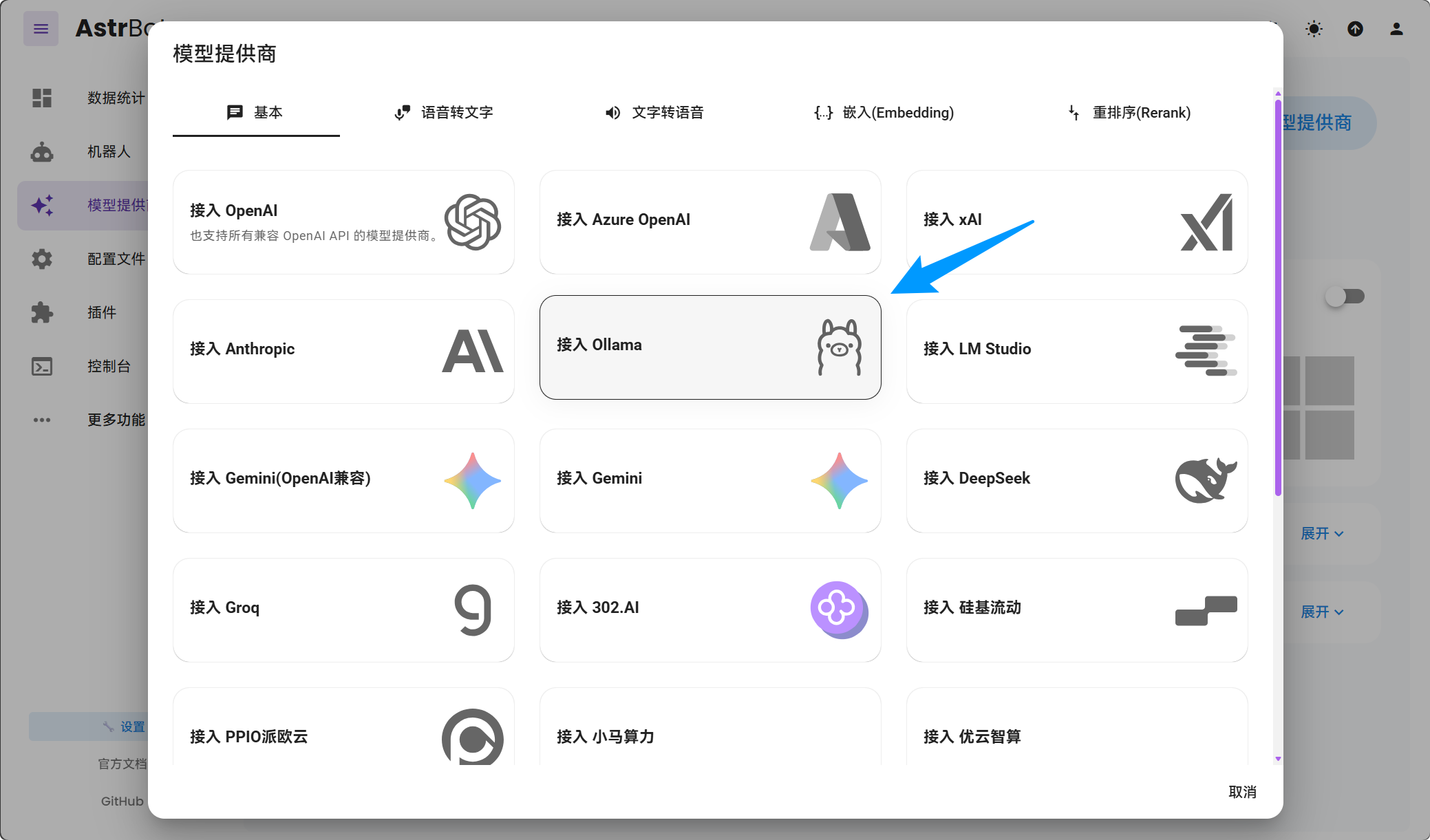
Save the configuration.
TIP
For Mac/Windows users deploying AstrBot with Docker Desktop, enter http://host.docker.internal:11434/v1 for the API Base URL.
For Linux users deploying AstrBot with Docker, enter http://172.17.0.1:11434/v1 for the API Base URL, or replace 172.17.0.1 with your public IP address (ensure that port 11434 is allowed by the host system).
If Ollama is deployed using Docker, ensure that port 11434 is mapped to the host.
FAQ
Error:
AstrBot request failed.
Error type: NotFoundError
Error message: Error code: 404 - {'error': {'message': 'model "llama3.1-8b" not found, try pulling it first', 'type': 'api_error', 'param': None, 'code': None}}Please refer to the instructions above and use ollama pull <model_name> to pull the model, then use ollama run <model_name> to run the model.